Chapter 10: Responsible AI Lifecycle¶
Overview¶
The good news is, a few years ago, you'd need to do all this yourself – build those dashboards, manually monitor thousands of signals and interpret them in time to save your operations from going down. But now, all the steps I highlight today can be done with Azure AI Foundry and across the whole Microsoft AI Suite. You can operationalize AI responsibly, hand in hand with AI as your copilot.
These are the essential development steps we use in our own engineering teams, and these steps will guide our conversation today.
Now, this makes the process look somewhat linear. Like any software development process, it's totally iterative and filled with experimentation.
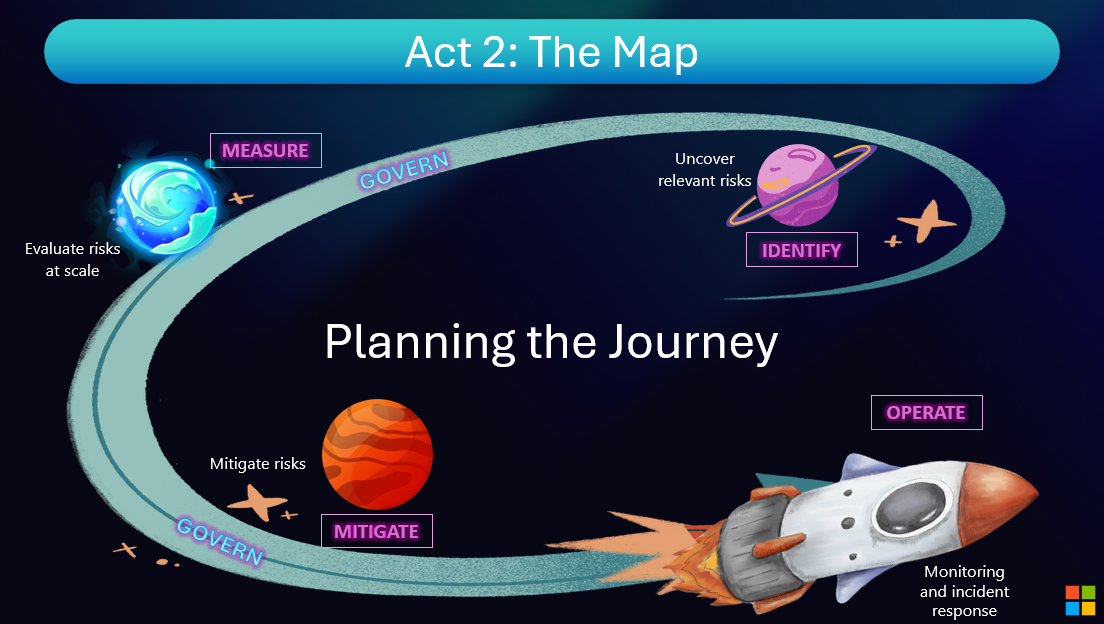
We'll go through each of these steps in more depth, but here's a quick overview:
- First, note this governance layer. At Microsoft, we have AI principles and governance processes that define our product requirements and serve as our north star.
- As soon as we have a business use case requiring generative AI, we work to identify the potential risks that could result from the AI system, so we know what we need to look out for.
The Responsible AI Lifecycle in Practice¶
Azure AI Foundry implements Microsoft's responsible AI lifecycle end-to-end:
- Map: Identify potential harms and risks specific to your use case
- Measure: Evaluate quality and safety using built-in and custom metrics
- Mitigate: Apply layered defenses (model, safety system, prompt, UX)
- Operate: Monitor continuously with real-time telemetry and feedback loops
This isn't just a conceptual framework—it's operationalized in Azure AI Foundry's tools, from the evaluation SDK to content safety filters to Application Insights monitoring. Every phase is supported by production-grade infrastructure, tested at Microsoft scale.
Resources and Further Reading¶
- We also measure how prevalent the risks are in our AI system, so we know where to focus our attention.
- We also leverage tools and techniques to mitigate those risk, using strategies such as prompt engineering, grounding, and content filters.
- We then look at strategies for deployment and operational readiness, including setting up monitoring so we can continually improve our app in production.
Resources and Further Reading¶
Online Resources¶
Next Steps¶
Continue your learning journey:
Questions or feedback? Join the discussion on our GitHub repository or connect with the community.